Project Overview
This project presents a complete Agentic AI Retrieval-Augmented Generation (RAG) System built to answer user questions intelligently from multiple knowledge sources. Unlike traditional single-source RAG systems, this project integrates four distinct data types into one unified intelligent interface.

System overview — RAG, AI Assistant, and Knowledge Base working together
Knowledge Sources
- Website documentation (OpenAI Agent SDK docs)
- PDF and company documents
- YouTube video transcripts (via Whisper AI)
- Structured and unstructured text files
Vector Stores
- FAISS — website & document embeddings
- ChromaDB — video transcript embeddings
- all-MiniLM-L6-v2 embedding model
- Agentic routing selects correct DB per query

Agentic AI Document Intelligence System — transforming multiple data sources into real-time answers
Problem Statement
Modern businesses store knowledge across multiple formats — internal policy documents, product documentation, training videos, and reports. Traditional chatbots and Q&A systems fail because they are single-source and cannot route intelligently between knowledge bases.

Organizations struggle with scattered knowledge across documents, websites, videos, and internal systems
Single-Source Limitation
Traditional systems are trained or indexed on only one type of data — making cross-format queries impossible.
No Intelligent Routing
Systems cannot autonomously decide which knowledge base to query based on the user's question intent.
Keyword Search Fails Semantically
Standard keyword-based retrieval misses contextually relevant results — semantic understanding is required.
Video Knowledge is Locked
Hours of training videos and recorded content remain unsearchable — critical knowledge is trapped in audio form.
The Challenge: Build a unified intelligent system that reads from all these sources, stores them semantically, and answers any question from the correct source — automatically.
Solution
The Agentic AI RAG System unifies all knowledge into one conversational interface. An agentic decision layer powered by the OpenAI Agents SDK autonomously selects the correct knowledge base per query and uses Gemini 2.0 Flash to generate accurate, context-aware responses.

A unified AI system that connects organizational knowledge and delivers context-aware answers instantly
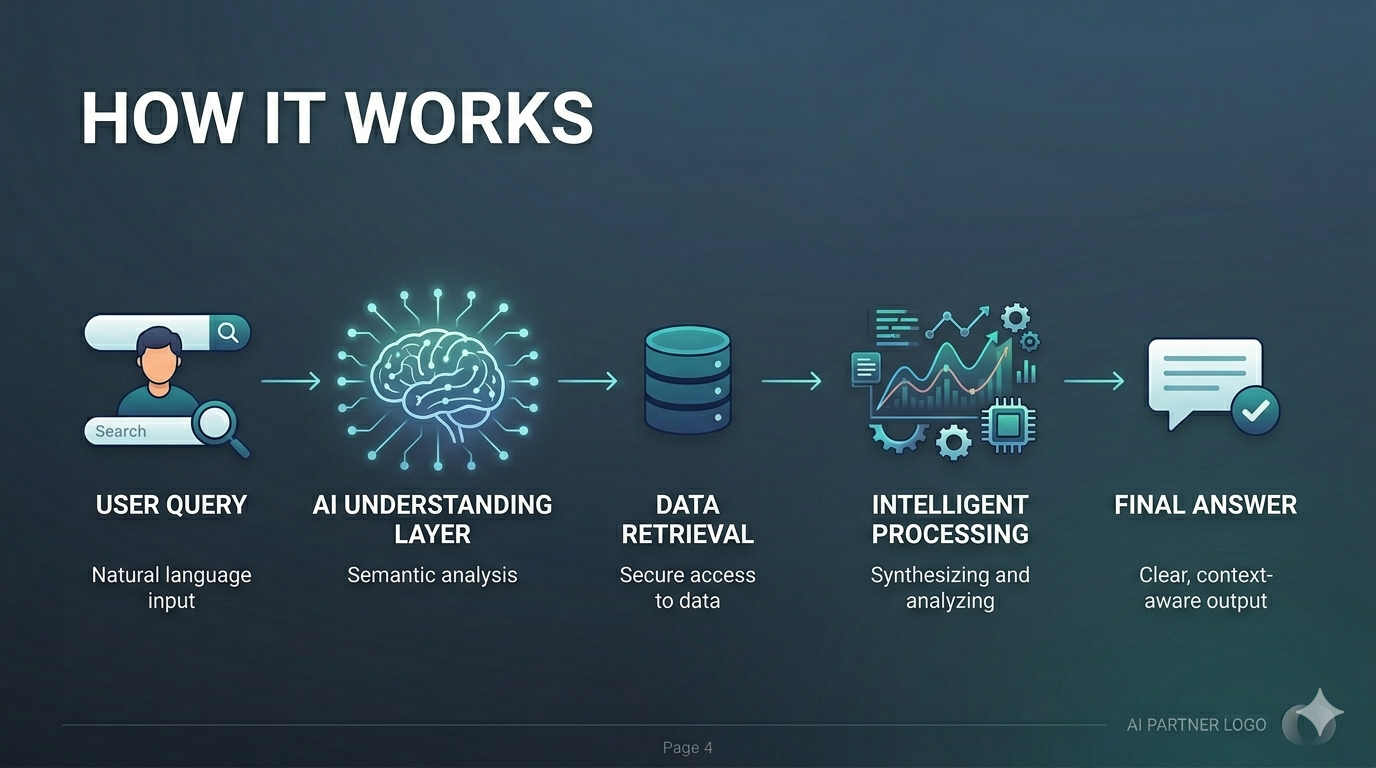
End-to-end flow: User Query → AI Understanding → Data Retrieval → Intelligent Processing → Final Answer
System Architecture
The system is built in two phases: a one-time setup phase for data ingestion and embedding, and a real-time query phase where the agent routes and retrieves.
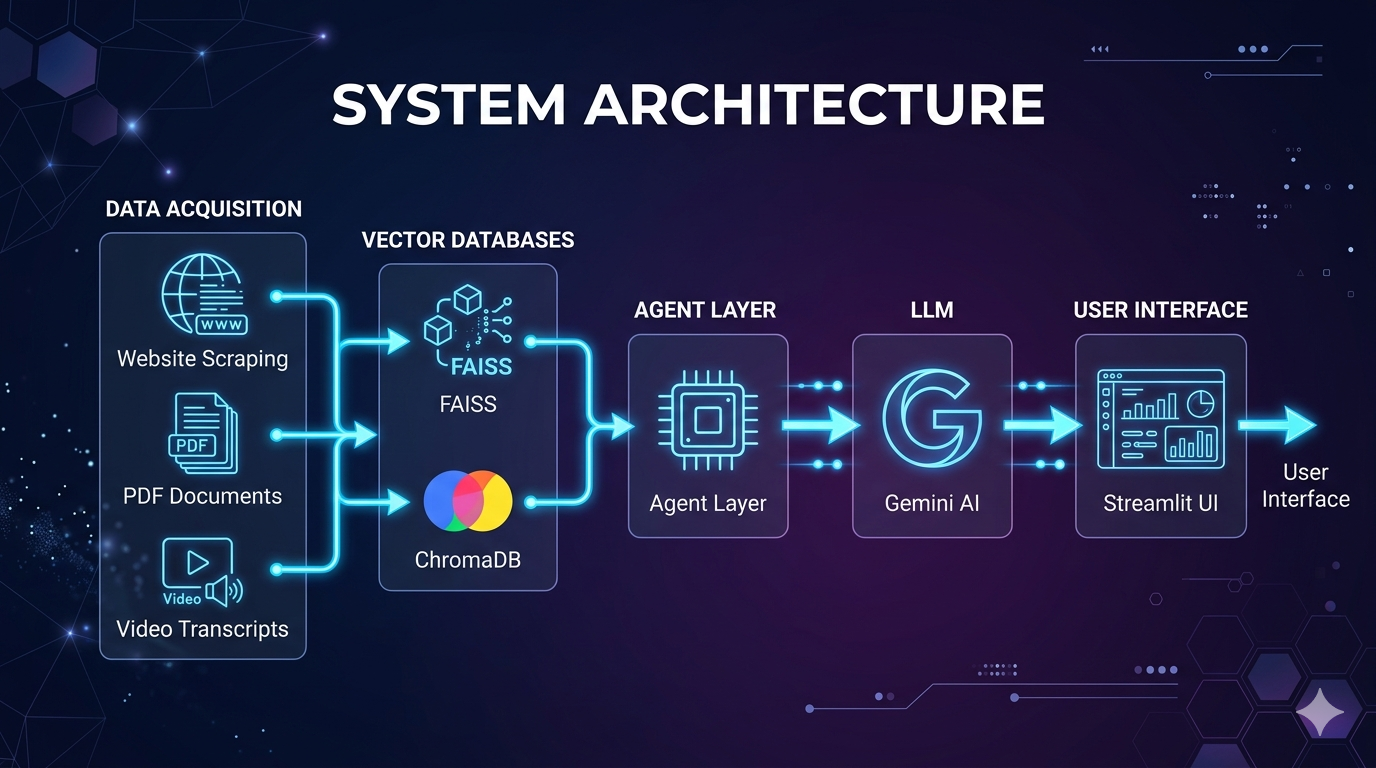
Full system architecture: Data Acquisition → Vector Databases → Agent Layer → LLM → Streamlit UI
┌─────────────────────────────────────────────────────────────┐
│ USER QUERY (Streamlit UI) │
└────────────────────────┬────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ AGENTIC LAYER (OpenAI Agents SDK) │
│ │
│ ┌─────────────────┐ ┌──────────────────────────┐ │
│ │ answer_query │ │ answer_from_video │ │
│ │ (Tool 1) │ │ (Tool 2) │ │
│ └────────┬────────┘ └────────────┬─────────────┘ │
└────────────┼─────────────────────────────┼────────────────-┘
│ │
▼ ▼
┌────────────────────┐ ┌───────────────────────────┐
│ FAISS Index │ │ ChromaDB Vector Store │
│ (Website Docs + │ │ (Video Transcript │
│ PDF/Documents) │ │ Embeddings) │
└────────────────────┘ └───────────────────────────┘
│ │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ Gemini 2.0 Flash LLM │
│ (via OpenAI-compatible API)│
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ FINAL ANSWER │
│ (Streamed to Streamlit) │
└─────────────────────────────┘
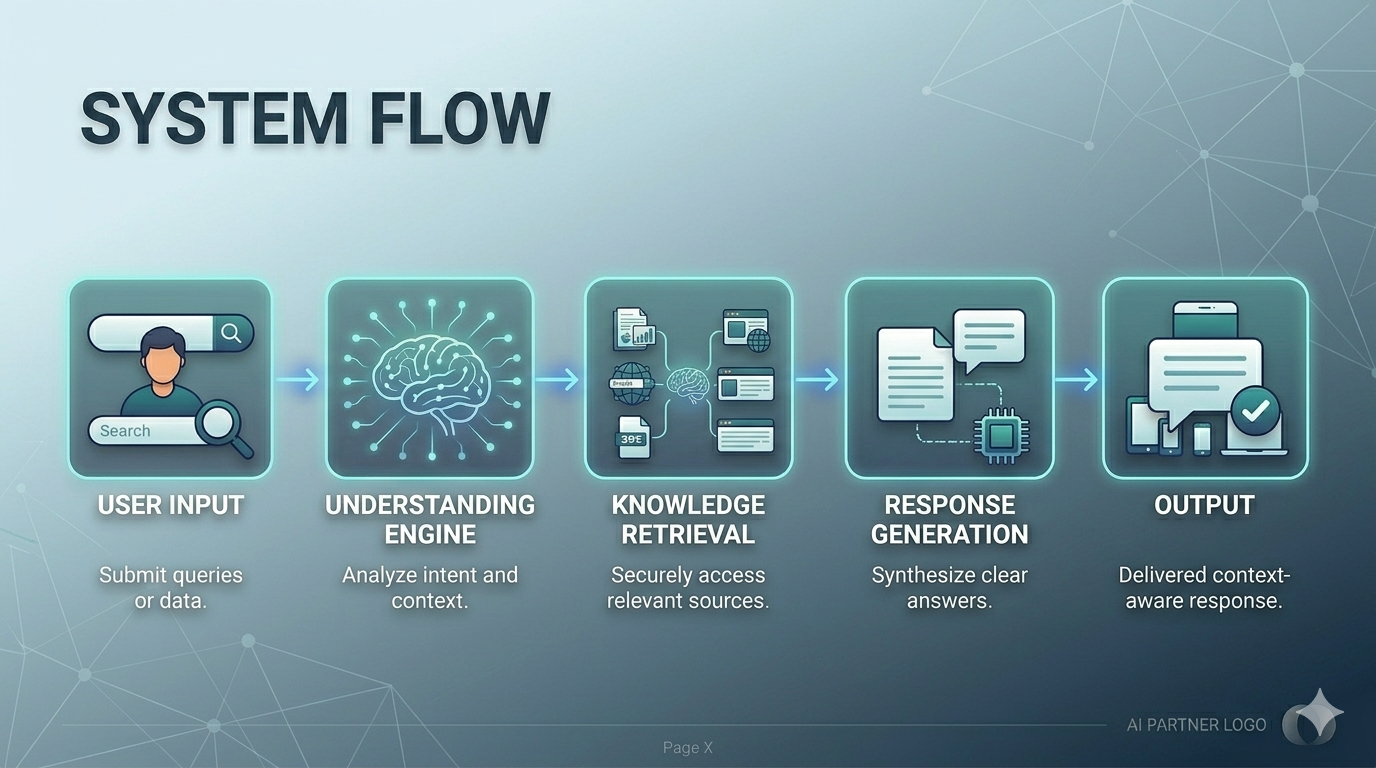
System flow: User Input → Understanding Engine → Knowledge Retrieval → Response Generation → Output
Data Pipeline
Each knowledge source has a dedicated ingestion pipeline that processes raw content into searchable vector embeddings.
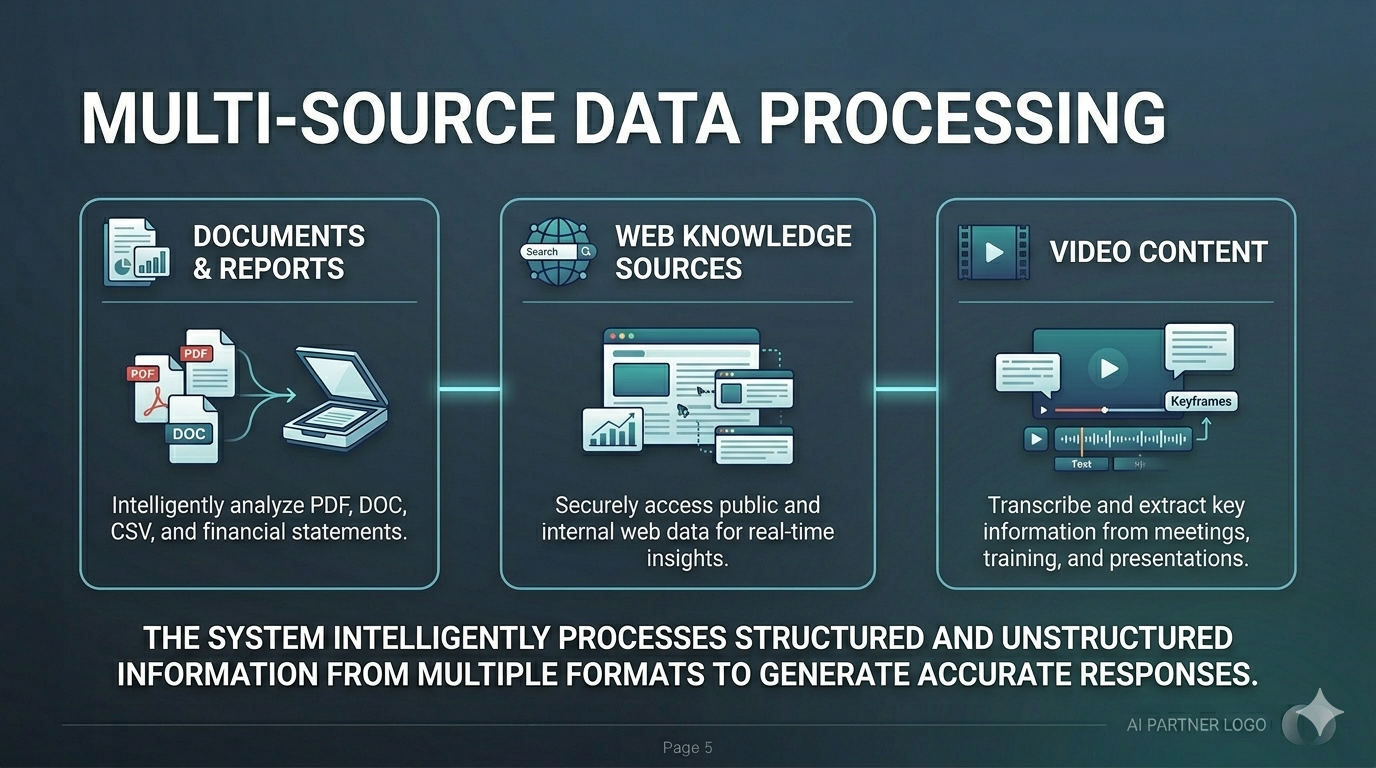
Multi-source data processing — Documents, Web Knowledge Sources, and Video Content all processed intelligently
Website Scraping Pipeline
BeautifulSoup4 recursively scrapes all pages of the OpenAI Agent SDK documentation. Extracts text from p, li, code, pre, h1–h3 tags, follows all internal links, and saves scraped pages as scraped_pages.pkl.
Chunking & FAISS Embedding
Text is chunked into 500-character segments with 50-character overlap to prevent context loss at boundaries. Embedded using all-MiniLM-L6-v2 (HuggingFace) and stored in a FAISS IndexFlatL2 for exact L2-distance retrieval.
Video Processing Pipeline
YouTube videos are downloaded with yt-dlp, then transcribed locally using faster-whisper (Whisper base, int8 quantized — CPU friendly). Transcript chunks are embedded and stored separately in ChromaDB for clean domain separation.
PDF & Document Processing
Business PDFs (HR policies, financial reports, internal SOPs) are processed via PyPDF2 or LangChain's PyPDFLoader. Extracted text follows the same 500/50-char chunking strategy and is embedded into the FAISS index alongside website data — making all document types queryable through the same agent interface.
Agentic Intelligence Layer
The core of the system is an agent built with the OpenAI Agents SDK that reasons about which tool to call based on query intent — rather than using a simple retrieval loop.
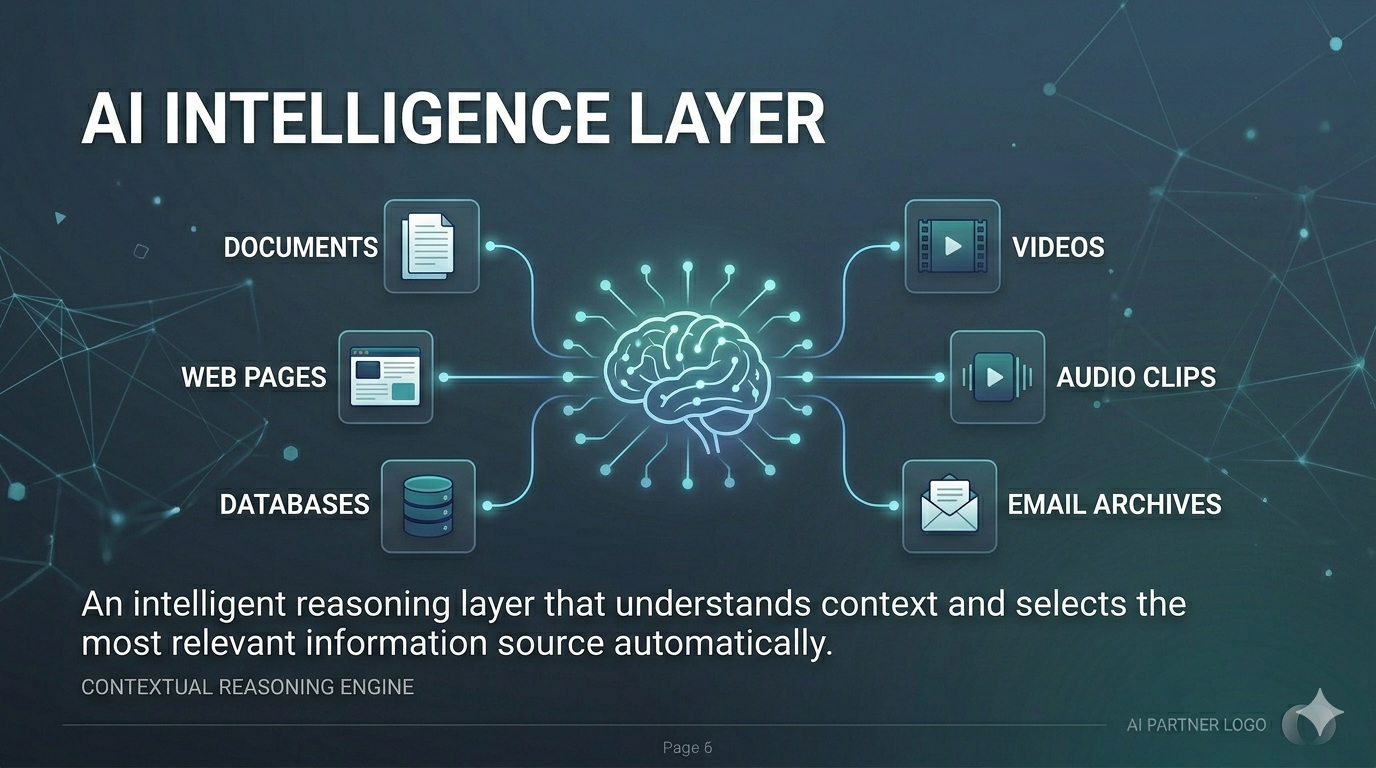
The AI intelligence layer understands context and selects the most relevant information source automatically
Tool 1 — Website & Document Search
answer_query(query) performs semantic search across the FAISS index of website documentation and PDF content. Retrieved chunks are passed as context to Gemini Flash for answer generation.
Tool 2 — Video Transcript Search
answer_from_video(query) embeds the query, performs semantic search in ChromaDB, retrieves top-5 transcript chunks, and generates a response using Gemini Flash — keeping video knowledge fully accessible.
Intelligent Routing Logic
The agent reads the user's question and selects the right tool based on intent — documentation questions go to FAISS, video questions go to ChromaDB. For cross-source questions, the agent calls both tools and Gemini synthesizes a unified answer.
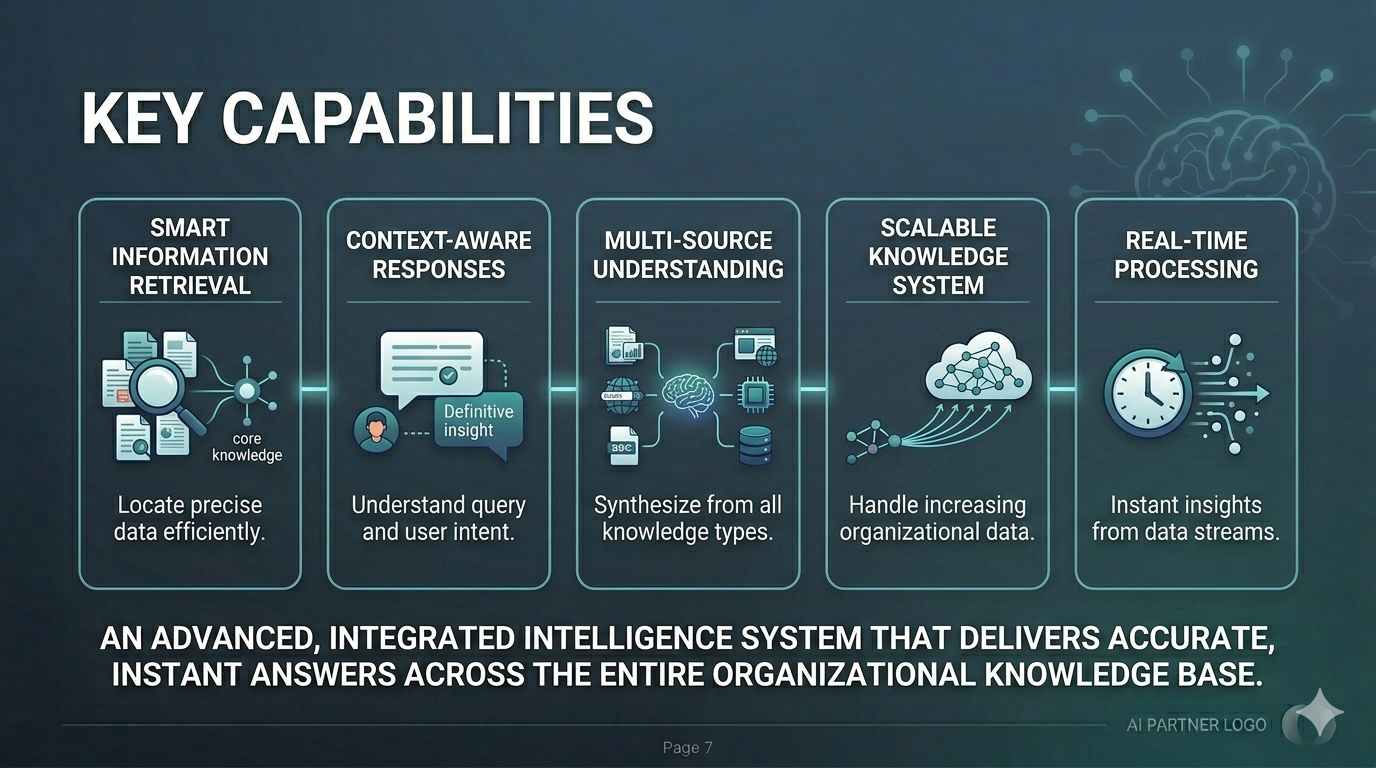
Key capabilities: Smart retrieval, context-aware responses, multi-source understanding, scalable, real-time processing
Use Case Demonstrations
The system handles a wide range of real-world queries by autonomously routing to the right knowledge source.

Three core use cases: Enterprise Knowledge Assistant, Training & Learning Assistant, Internal Document Intelligence
"How can I extend an Agent with a custom tool?"
Routed to answer_query → FAISS search on OpenAI SDK docs → Gemini explains @function_tool decorator with examples
"What was explained about tool selection in the Agentic AI video?"
Routed to answer_from_video → ChromaDB semantic search on transcript → Gemini extracts and explains the relevant section
"What is the company leave policy in the HR document?"
Routed to answer_query → FAISS search on indexed PDF content → Gemini retrieves and explains the leave policy
"Generate 5 MCQs about handoffs and guardrails in the OpenAI SDK"
Routed to answer_query → Retrieves relevant context → Gemini generates 5 MCQs with correct answers
"Give a summary of tracing in Agentic AI from both docs and video"
Agent calls answer_query AND answer_from_video → Gemini synthesizes information from both sources into a unified summary
Technology Stack
| Layer | Technology | Purpose |
|---|
| Web Scraping | BeautifulSoup4, Requests | Extract text from documentation website |
| Video Download | yt-dlp | Download YouTube videos as MP4 |
| Audio Transcription | faster-whisper (base, int8) | Convert video speech to text on CPU |
| PDF Processing | PyPDF2, LangChain | Extract text from PDF documents |
| Text Chunking | Custom Python (500 chars, 50 overlap) | Split text for vector retrieval |
| Embedding Model | all-MiniLM-L6-v2 (HuggingFace) | Generate 384-dim semantic embeddings |
| Vector DB 1 | FAISS (IndexFlatL2) | Store & search website & document embeddings |
| Vector DB 2 | ChromaDB (PersistentClient) | Store & search video transcript embeddings |
| Agent Framework | OpenAI Agents SDK | Intelligent tool routing and orchestration |
| LLM | Gemini 2.0 Flash (OpenAI-compatible API) | Natural language response generation |
| Frontend | Streamlit | Interactive web UI with streaming responses |
| Environment | python-dotenv, uv | Secure config and dependency management |
Challenges & How They Were Solved
Multiple knowledge sources with different formats
Built separate ingestion pipelines per source type — scraper for websites, Whisper for video, PyPDF2 for documents. Each produces the same embedding format so the agent treats all sources uniformly.
Agent picking the wrong knowledge base
Added explicit MUST directives in the agent's system prompt — e.g., "You MUST use answer_from_video for video-related questions." This dramatically improved routing accuracy.
Video files too large for direct processing
Download with yt-dlp first, then transcribe locally using Whisper base (int8 quantized). The int8 quantization makes the model 8x smaller and CPU-compatible while maintaining good accuracy for English content.
ChromaDB ID conflicts on re-run
Implemented a delete-before-add strategy for video chunks — existing IDs are removed before re-adding new embeddings, preventing duplicate document conflicts in the persistent ChromaDB store.
Streaming responses in Streamlit
Used Runner.run_streamed() with an async event loop inside Streamlit. Each ResponseTextDeltaEvent updates the placeholder in real-time, creating a word-by-word streaming effect.
Using Gemini with OpenAI Agents SDK
Gemini 2.0 Flash exposes an OpenAI-compatible endpoint. By configuring AsyncOpenAI with Gemini's base URL and API key, the agent code required zero changes — a true drop-in replacement.
Results & Business Value

Business value delivered: faster decisions, reduced manual search time, unified knowledge access, improved productivity
4 Sources
Web, PDF, Video & Docs unified
Real-Time
Streaming word-by-word answers
Auto-Route
Agent picks correct source per query
Modular
Any new source = new tool + index
The system solves a real business problem: organizations store knowledge in multiple formats, and employees waste time searching across systems. This RAG agent unifies all knowledge into one conversational interface — reducing information retrieval from hours to seconds.
Scalability & Future Enhancements
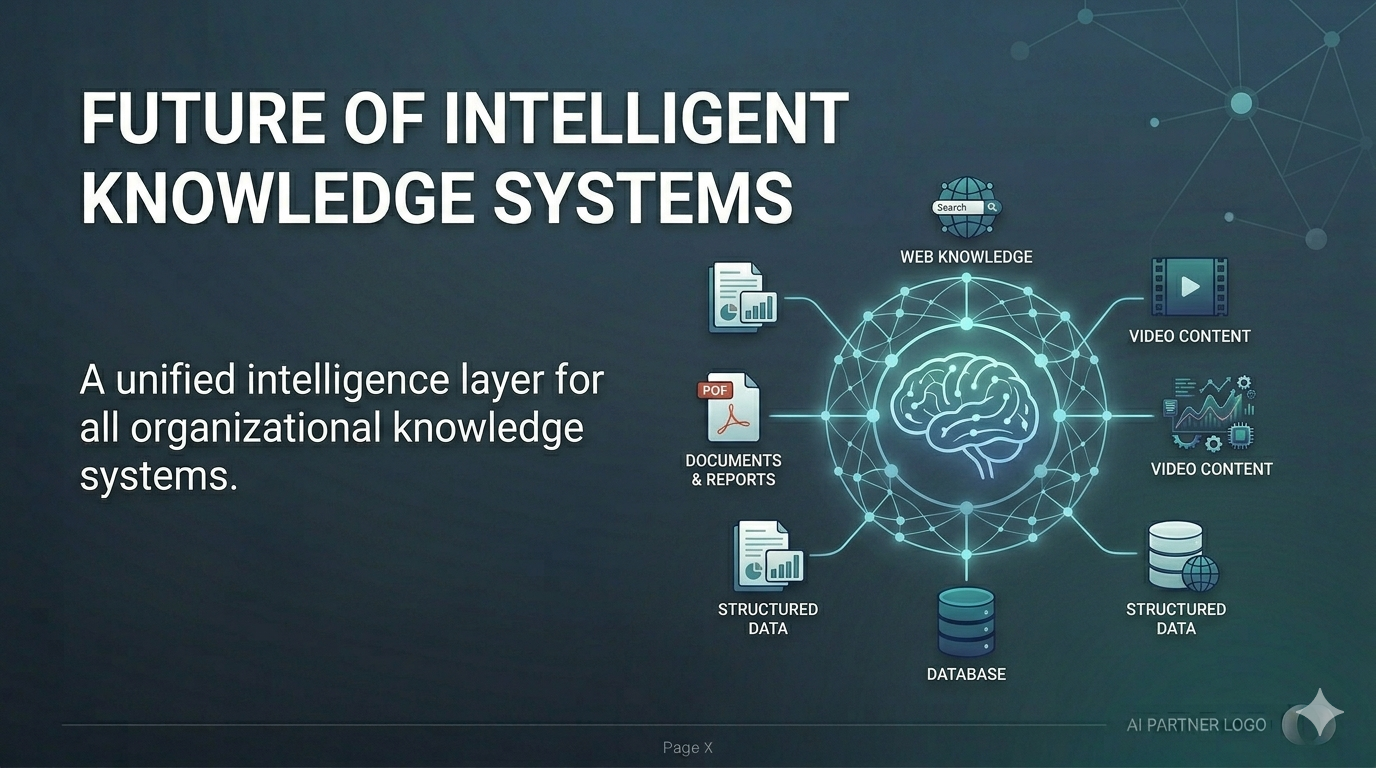
The future of intelligent knowledge systems — a unified intelligence layer for all organizational knowledge
1
PDF Pipeline Completion
Fully activate the RagPDF module with PyPDF2 and LangChain loaders for batch document ingestion.
2
Multi-language Support
Whisper supports 99 languages — extend transcript processing for non-English video content.
3
Re-ranking Layer
Add cross-encoder re-ranking after vector retrieval to improve precision on complex queries.
4
Hybrid Search
Combine BM25 keyword search with semantic vector search for improved recall on exact-match queries.
5
Document Upload UI
Allow users to upload PDFs directly through Streamlit — no code changes needed to add new content.
6
Async Ingestion
Background processing for new documents so the system remains online while ingesting new knowledge.
Want a similar AI solution for your business?
We build custom Agentic AI and RAG systems that unify your knowledge base and make information retrieval instant.
